今天我們要來搭建一個簡易模型,這個模型能夠將輸入的圖片做分類的動作,並且要經過多層神經網路的訓練,從而訓練出我們的 DNN 模型,在建模前先來了解下面的基本概念吧 ~
一張圖片在電腦眼中是由一格格像素 ( Pixel ) 為元素所組成的三維陣列,可以用 0 代表該格像素顏色為黑,1 為白,那我們通常會用 0 ~ 255 值來表示 0 是最黑,255 是最白,如此一來就可以畫出一張灰階圖片。
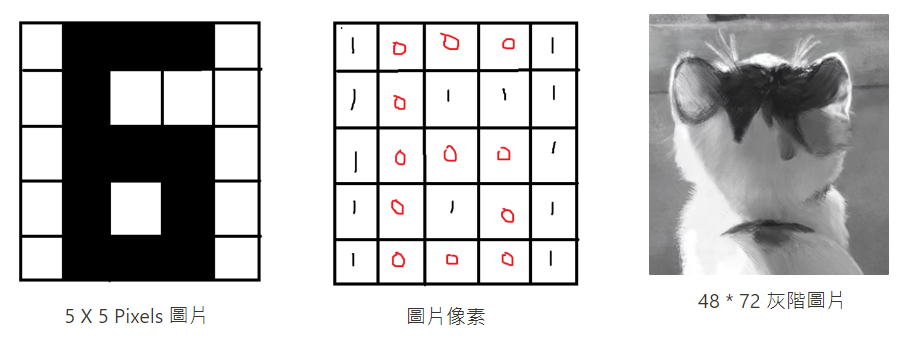
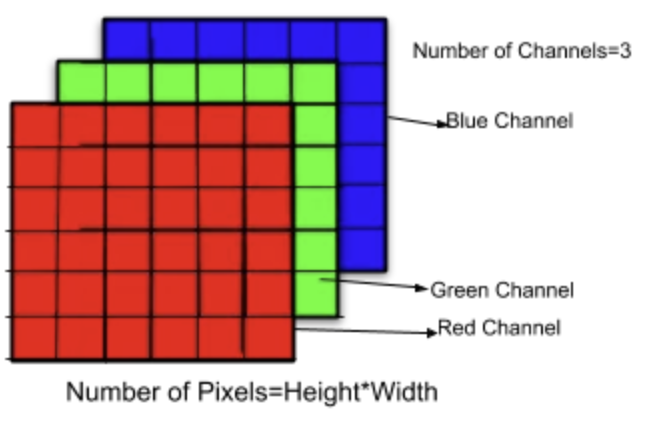
一張彩色圖片是由 RGB 紅綠藍三層 ( 三通道 ) 所疊加組合起來,而每個層便是由像素 Pixels ( 值域 : 0 ~ 255 ) 所組成的二維陣列,最後三層疊加在一起變成三維的陣列,所以在取得彩色圖片的一處的像素時,得到的是該處在各個通道間的像素大小,在將這些值組合起來,如同下圖的 [28 , 70 , 50]。
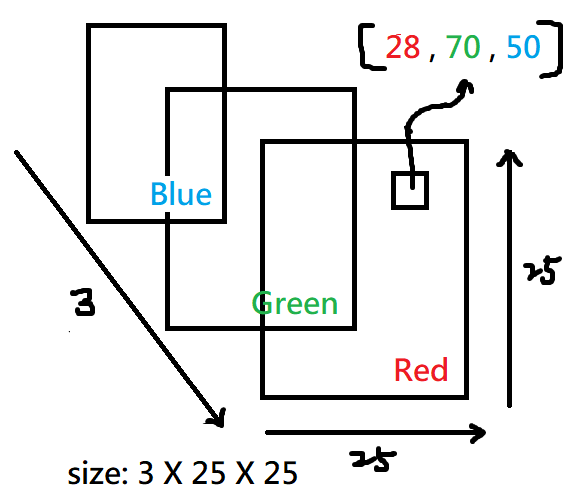
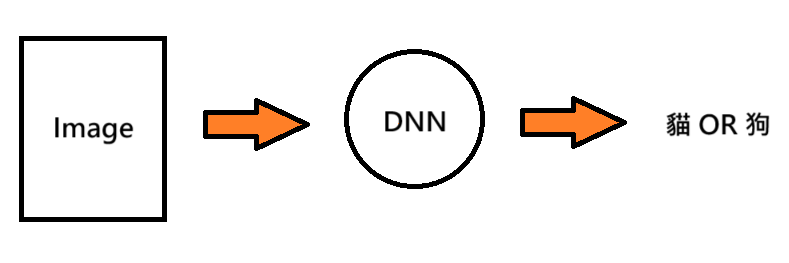
在二元分類的情況中,我們用圖片作為特徵,假設是一張 25 * 25 的彩色圖片 Image,輸入製模型的特徵就會有 3 * 25 * 25 個,就等於是把三維的圖片攤平成一維的資料輸入,在特徵很多的情況下我們可以把特徵資料丟到較複雜的神經網路去訓練,經過模型藉由激勵函數 Sigmoid function 預測出一個機率值,最後判斷如果機率 ≥ 0.5 就為貓,else 不是貓 ( 狗 ),簡易架構如下:
假設現在要預測圖片是三個 class ( 貓、狗、牛 ) 中的哪個 class,和二元分類不一樣的是我們會希望 model 最後輸出三個值,這三個值就代表 [ 屬於各自對應到的 class 的機率 s (x) ],第一個值就是圖片屬於第一個 class ( 貓 ) 的機率,第二個值就是圖片屬於第二個 class ( 狗 ) 的機率依此類推,要得到 s (x) 就會經過 softmax function 的計算,所以 class 的個數就決定了 model 輸出值有幾個,簡單架構如下:
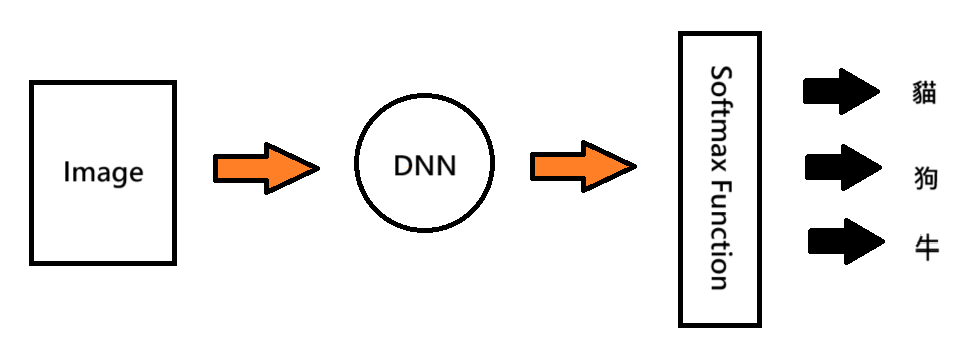
如果有四個 class,此函數輸入為模型輸出四個值 ( 不會經過 sigmoid function ),把四個值代入 softmax function 後就會得到四個值各自對應的 class 的機率,算法公式如下:
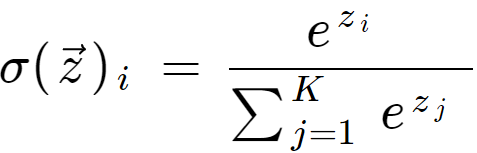
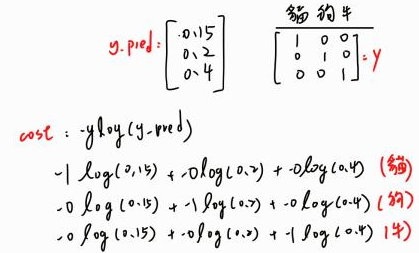
我們使用 Cross Entropy 來作為計算成本的方法,得到公式 : ,其中
就是 model 輸出的個數 ( class 數量 ),就可以知道每筆特徵資料 ( 每張圖 ) 預測出來的 y_pred 和真實結果 y 之間的成本大小,值得注意的是在計算成本時可以把貓看成是 [ 1 , 0 , 0 ],狗 [ 0 , 1 , 0 ],牛 [ 0 , 0 , 1 ] 來區分 label 間的不同,這樣一來就可以讓 label 等於貓時可以代入
函數中,label 不是貓時就代入就無意義 (
)。
from torchvision import datasets # 導入 pytorch 資料集
from torchvision.transforms import ToTensor # 圖片轉為Tensor
import matplotlib.pyplot as plt
import random
from torch.utils.data import DataLoader # 將資料批量
from torch import nn
Datasets — Torchvision 0.15 documentation
在資料的部分我們可以使用 Torchvision 套件提供的內建資料集,到上面的官網可以看到各種對於不同 task 的提供的資料集,我們這邊是要作圖片的分類,因此在下面程式碼中挑選 FashsionMNIST 作為資料集並引入,裡面有 60000 張 28 * 28 的灰階圖片訓練資料和 10000 張 28 * 28 張圖片做為測試資料。
接著設定參數 download 為 True 把資料下載下來,下載到的資料夾可以在 root 參數設定,這邊設定下載到 image 資料夾,train 參數為 True 得到的資料就是訓練資料,False 就是測試資料,並且 transform 參數 = ToTensor() 把資料都轉為 Tensor 型態才能夠將圖片分成一個個 pixel 作為特徵資料:
train_data = datasets.FashionMNIST(
root="image", train=True, download=True, transform=ToTensor())
test_data = datasets.FashionMNIST(
root="image", train=False, download=True, transform=ToTensor())
把第一筆特徵資料 ( 第一張圖 ),印出來看,按照之前得到的資料值應該介在 0 ~ 255 之間,但是這邊它已經幫我們做特徵縮放了,所以值會介在 0 ~ 1 之間:
train_data[0][0]
Ouput:
tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0039, 0.0000, 0.0000, 0.0510,
0.2863, 0.0000, 0.0000, 0.0039, 0.0157, 0.0000, 0.0000, 0.0000,
0.0000, 0.0039, 0.0039, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.0000, 0.1412, 0.5333,
0.4980, 0.2431, 0.2118, 0.0000, 0.0000, 0.0000, 0.0039, 0.0118,
0.0157, 0.0000, 0.0000, 0.0118],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0235, 0.0000, 0.4000, 0.8000,
0.6902, 0.5255, 0.5647, 0.4824, 0.0902, 0.0000, 0.0000, 0.0000,
0.0000, 0.0471, 0.0392, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
...
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]])
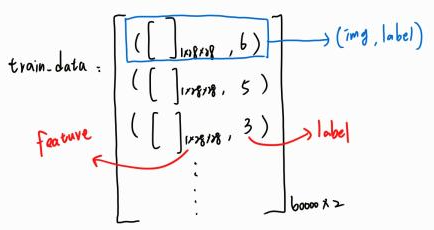
得到的 train_data 可以把它想成長這樣 : 藍色框線就是第一筆訓練資料,包含 1 * 28 * 28 大小的特徵資料和標籤,標籤為 6 就表示該圖片屬於 train_data.classes [6] 類別,把 train_data.classes 印出
來就會發現它其實就是存放類別名稱的字串 list :
['T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot']
要從 60000 張圖片隨機取樣,我們就要有一個隨機的 rand_idx 值,代表隨機的位置 ( index ),因此值範圍 [ 0 , 60000 ),隨機取樣到的資料為 tuple 型態,其值分別為圖片特徵和標籤,分別設給 img , label,再把取樣圖片用 plt.imshow() 畫出來,可是我們現在的 img 變數大小為 1 * 28 * 28,在畫圖時 matplotlib 會要求我們把顏色通道的維度放在最後一個,所以我們要對 img 做 permute() 維度順序轉換,把原本的第 1 維放在第 0 維,第 2 維放在第一維,第 0 維放在最後一維:
rand_idx = random.randint(0, len(train_data) - 1) # random index: [0, 60000)
img, label = train_data[rand_idx] # tuple type
class_names = train_data.classes # 類別 list
plt.imshow(img.permute(1, 2, 0), cmap="gray") # 沒有設定cmap預設為彩色圖片
plt.title(class_names[label]) # 引出類別
plt.show()
我們之前在做 Gradient Descent 時,model 會先看過所有的訓練資料,但如果資料過多時可能就沒辦法,電腦記憶體可能無法負擔,又或者是能夠看完所有資料但參數更新的速度過慢,這樣不管對測試還是訓練過程來說都是不好的,因此我們就會對資料做分批,讓 model 每次只看其中一小批資料就去更新參數,像是有 60000 筆訓練資料我們就讓 model 每次只看 32 筆資料,這樣總共就會有 1875 ( 60000 / 32 ) 批訓練資料,測試資料也是如此,為了讓訓練效果更加,在分批的時候會把訓練資料打亂 ( shuffle = True ):
# training data Batch
train_dataLoader = DataLoader(
train_data,
batch_size=32,
shuffle=True
)
# testing data Batch
test_dataLoader = DataLoader(
test_data,
batch_size=32,
shuffle=False
)
得到的 train_dataLoader 和 test_dataLoader 是可迭代物件, iter() 取得迭代器就可以用 next() 去迭代,第一次執行下面程式碼就會得到第一批訓練資料 ( 包含特徵和標籤 ),每次執行都 next() 都往下繼續迭代,得到的資料也會不一樣,可以把得到的資料印出來看,x_fist_batch 會是大小為 32 * 1 * 28 * 28,代表有 32 張 28 * 28 的灰階圖片做為特徵資料,y_first_batch 的每個元素都代表 class 在 class_names 中的位置:
x_first_batch, y_first_batch = next(
iter(train_dataLoader)) # [(feature, label), (),...,()]
x_first_batch, y_first_batch
隨機取樣第一批的資料,因為每批都有 32 筆資料,所以 rand_idx 的隨機取值範圍介於 [ 0 , 32 ),再把圖畫出:
rand_idx = random.randint(0, len(x_first_batch) - 1) # range [0, 32)
img, label = x_first_batch[rand_idx], y_first_batch[rand_idx]
plt.imshow(img.permute(1, 2, 0), cmap="gray")
plt.title(class_names[label])
plt.show()
我們之前提到每張圖片都是 1 * 28 * 28 的三維 tensor,在輸入到神經網路前必須要拉直為一維 tensor,所以就要做圖片特徵攤平的動作,會用到 nn.Flatten() 建立攤平的物件 f,它的參數 start_dim可以設定要從哪一維開始攤平以及 end_dim 設定攤平到哪一維結束,下面程式碼就可以把三維的圖片攤平成一維
f = nn.Flatten(start_dim=0, end_dim=-1) # 第0維開始攤平到最後一維
f(x_first_batch[0]).shape # torch.Size([784])
現在我們就要來用 Pytorch 搭建 DNN 模型了,若想要你的 DNN 更加複雜 ( 隱藏層數量更多 ),可以用 nn.Sequential() 把層跟層之間串接起來,而我們在訓練時並不是一張一張圖片餵給 model,而是以 Batch 為單位,而大小為 32 * 1 * 28 * 28 的 Batch 資料在傳進去後只需要攤平圖片不用把所有圖片都一起攤平,所以 nn.Flatten() 從第 1 維開始攤平就好,Batch 資料大小最後會變成 32 * 784,然後把 model 的輸出 ( 大小 32 * 10 ) 的第一維 ( dim = 1 ) 進行 Softmax() 處理,就會讓每張圖片經過 model 輸出後的 10 個值相加為 1,下面為模型的架構,是個僅有輸入層和輸出層的神經網路:
class ImageClassificationModel(nn.Module):
def __init__(self, input_shape, output_shape):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=input_shape, out_features=output_shape),
nn.Softmax(dim=1)
)
def forward(self, x):
return self.layer_stack(x)
用 y_pred.argmax(dim=1) 就可以知道每張圖片屬於哪個類別的機率最大,4 就代表該圖片是 class_names[4] 的機率最大,圖片最有可能屬於該類別,如下:
torch.manual_seed(87)
model = ImageClassificationModel(28*28, 10)
y_pred = model(x_first_batch)
y_pred.argmax(dim=1) # return the index where the maximum is
Output:
tensor([4, 5, 2, 3, 7, 3, 7, 3, 2, 7, 2, 2, 2, 2, 7, 7, 2, 7, 2, 7, 3, 4, 7, 4,
3, 7, 2, 4, 4, 4, 5, 7])
在執行 model(x_first_batch) 對傳入資料做 nn.Linear() 時,可以想成是做一系列的矩陣運算,因此最後的 y_pred 大小為 32 * 10:
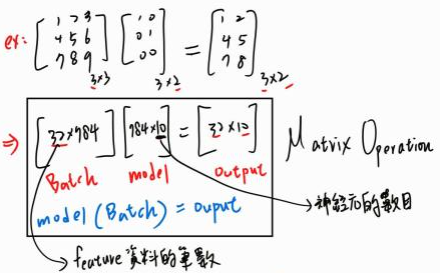
找出最佳解的方式一樣是用 SGD,這個 task 所使用的成本函數前面提到是用 CrossEntropy,之前的範例中在訓練時每次的 epoch model 會讀取所有的特徵資料,然後在做參數的更新:
from tqdm.auto import tqdm
epochs = 3
train_cost_hist = []
test_cost_hist = []
train_acc_hist = []
test_acc_hist = []
for epoch in tqdm(range(epochs)):
train_cost = 0
train_acc = 0
# enumerate(train_dataLoader):[(index, [feature, label]),(,),...,(,)]
# len(train_dataLoader): 1875
for batch, (x_batch, y_batch) in enumerate(train_dataLoader):
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
model.train()
train_pred = model(x_batch)
cost = crossEntropyLoss(train_pred, y_batch)
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_cost += cost
train_acc += accuracy(train_pred.argmax(dim=1), y_batch)
if(batch % 500 == 0):
print(f"看到第 {batch * len(x_batch)}/{len(train_data)} 筆資料")
train_cost /= len(train_dataLoader)
train_acc /= len(train_dataLoader)
train_cost_hist.append(train_cost.cpu().detach().numpy())
train_acc_hist.append(train_acc)
test_cost = 0
test_acc = 0
model.eval()
with torch.inference_mode(): # Inference Mode On (It's a context manager)
for x_batch, y_batch in test_dataLoader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
test_pred = model(x_batch)
test_cost += crossEntropyLoss(test_pred, y_batch)
test_acc += accuracy(test_pred.argmax(dim=1), y_batch)
test_cost /= len(test_dataLoader)
test_acc /= len(test_dataLoader)
test_cost_hist.append(test_cost.cpu().detach().numpy())
test_acc_hist.append(test_acc)
print(
f"epoch:{epoch: 2}, train_cost:{train_cost: .4e}, train_acc:{train_acc: .3e}%, testing_cost:{test_cost: .4e}, test_acc:{test_acc: .3e}%")
我們把剛才的 model 的神經網路架構做一些改良變成,讓它在複雜一點看會不會表現得比較好,原本在舊的模型架構中只有輸入和輸出層,而現在我們在中間再多加 2 個隱藏層 ( hidden layer ),讓輸入進來的圖片能夠經過更加複雜的計算,並設定每個隱藏層最後會經過 ReLU 激勵函數 ( 在做 gradient descent 比較快 ),最後一層輸出層會經過 softmax 函數就會得出結果,簡易架構如下:
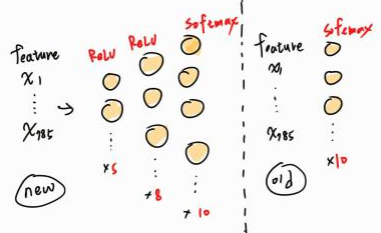
定義出新模型架構後再用剛剛的訓練模型方法訓練這個新模型,下面為新模型的架構:
class ImageClassificationModel2(nn.Module):
def __init__(self, input_shape, output_shape):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=input_shape, out_features=5),
nn.ReLU(),
nn.Linear(in_features=5, out_features=8),
nn.ReLU(),
nn.Linear(in_features=8, out_features=output_shape),
# 在傳入 crossEntropyLoss(input)後會做 Softmax(input)轉換
# nn.Softmax(dim=1)
)
def forward(self, x):
return self.layer_stack(x)
訓練完後再實做一個 eval_model 方法用來評估 model 最終的準確率和成本 ( 使用測試資料 ):
def eval_model(dataloader, model, cost_func, accuracy_fuc, device):
test_cost = 0
test_acc = 0
model.eval()
with torch.inference_mode(): # Inference Mode On (It's a context manager)
for x_batch, y_batch in test_dataLoader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
test_pred = model(x_batch)
test_cost += crossEntropyLoss(test_pred, y_batch)
test_acc += accuracy(test_pred.argmax(dim=1), y_batch)
test_cost /= len(test_dataLoader)
test_acc /= len(test_dataLoader)
return {
"model_name": model.__class__.__name__,
"model_cost": test_cost,
"model_acc": test_acc
}
新舊 model 在測試資料上的表現比較,會發現新模型相較於舊模型成本和準確率都較差 ,由此可知不同的神經網路的學習深度會影響著模型的效能表現:
model1_result = eval_model(test_dataLoader, model, crossEntropyLoss, accuracy, device)
model2_result = eval_model(test_dataLoader, model2, crossEntropyLoss, accuracy, device)
model1_result, model2_result
Output:
({'model_name': 'ImageClassificationModel',
'model_cost': tensor(0.5481),
'model_acc': tensor(81.5096)},
{'model_name': 'ImageClassificationModel2',
'model_cost': tensor(0.7063),
'model_acc': tensor(71.8750)})
今天我們所學到:
從一開始的資料的預處理、模型的設計搭建與訓練到最後的效能評估,希望大家藉由今天的簡易 DNN 實作,能夠更加熟悉模型的整體訓練過程,那我們就明天見 ~
https://medium.com/lets-talk-ml/image-data-lets-talk-in-numbers-7b6d4886b757

